






ChatRTX Ver0.3 (旧:Chat With RTX)でローカルLLM(大規模言語モデル)Nvidia製GPU:RTX4060Ti(16GB)で実行する
Chat RTX(旧:Chat With RTX)でローカルLLM(大規模言語モデル)を実行する
-
CPU:i9-13900K(渦中の奴)
-
メモリ(RAM):64GB
-
GPU:RTX4060Ti(16GB)&RTX A2000(6GB)
-
HDD/SSD:SynologyからiSCSI OS Boot (ロールバックを簡単に行うため) Chat RTXの保存/実行はNvme(Adata Falcon 512GB)
今回のChat RTXの実行環境は以下の通りです。
1.ChatRTXの取得先について
ChatRTXの取得については2024年5月10日現在、Nvidiaの公式ページでは、 旧Chat With RTXのページしか用意されておらず、英語版のページからファイルを取得する必要があります。
ダウンロードファイルについても、 Ver0.3よりインストール後に使いたいモデルをダウンロードする方法になり、 Ver0.2(旧:Chat With RTX)より 13GB近くの初期ダウンロードファイルが少なくなっています。
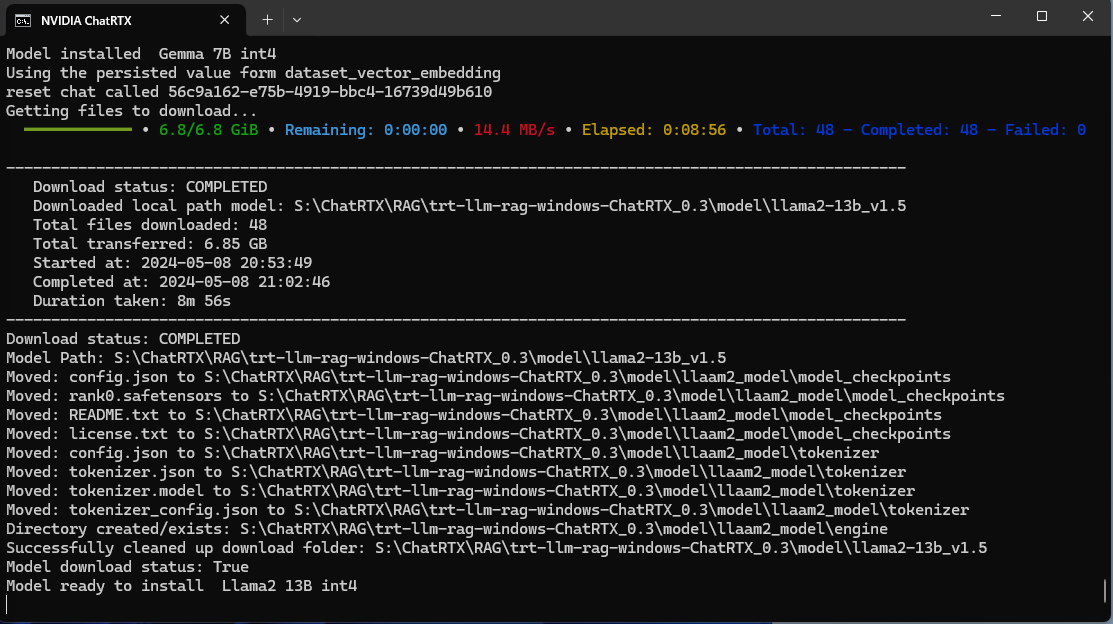
また、英語版のChat RTXのページ下部にある Chat for DevelopersのGit Hubへのリンクに関してですが、 こちらのリンク上のGit Hub上にあるTRT-LLMは v0.5およびv0.7.1と古い情報となっています。 Chat RTXで実行されるTRT-LLM(TensorRT-LLM for Windows)はVer0.9となり、 自分でモデルを追加したい等でなければ、あまり参考にならないかと思います。
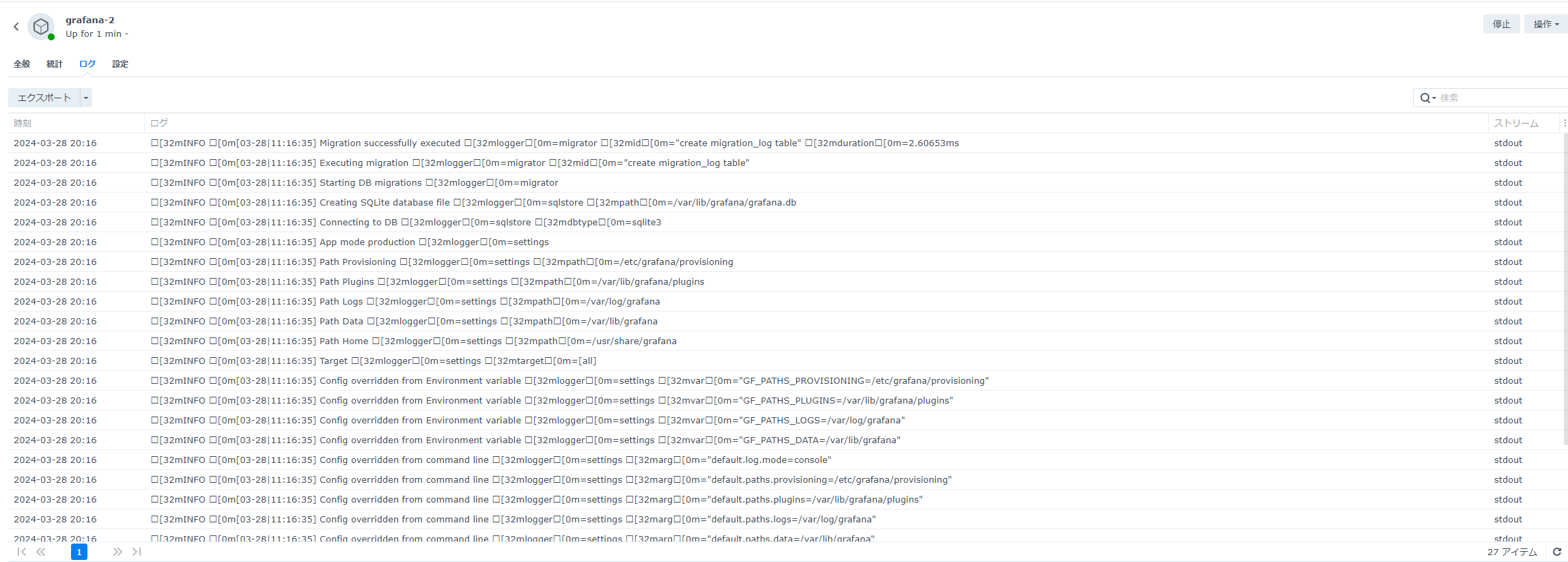
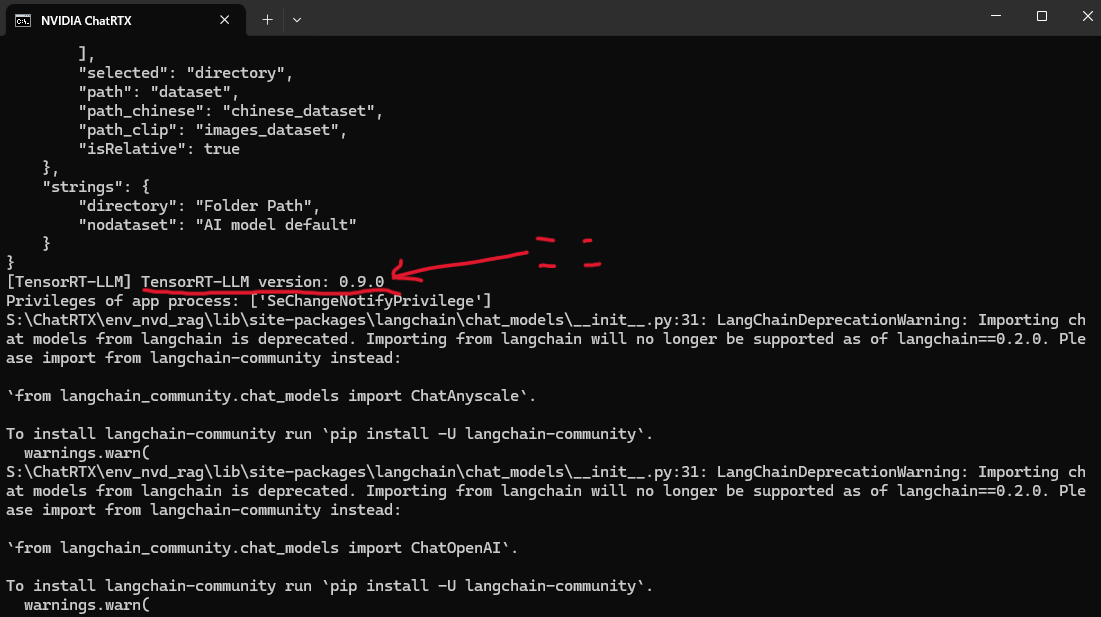
下記の画像中心部分あたりで、config.jsonのロード後にTensorRT-LLMがVer0.9.0で実行されているのがわかります。
また、インストール中に、ChatRTX側で「Mistral 7B int4」等のビルドをするらしく、もりもりメモリを持っていかれます。
VRAM・RAMともに16GB以上ないときつい状況だと思います。
また、起動すると以下のような画面になって、メモリをもりもり消費しながらChatRTXが起動してきます。
内部的にはPython3+minicondaで動いているようで、インストール時にPythonとminicondaの文字が確認できます。
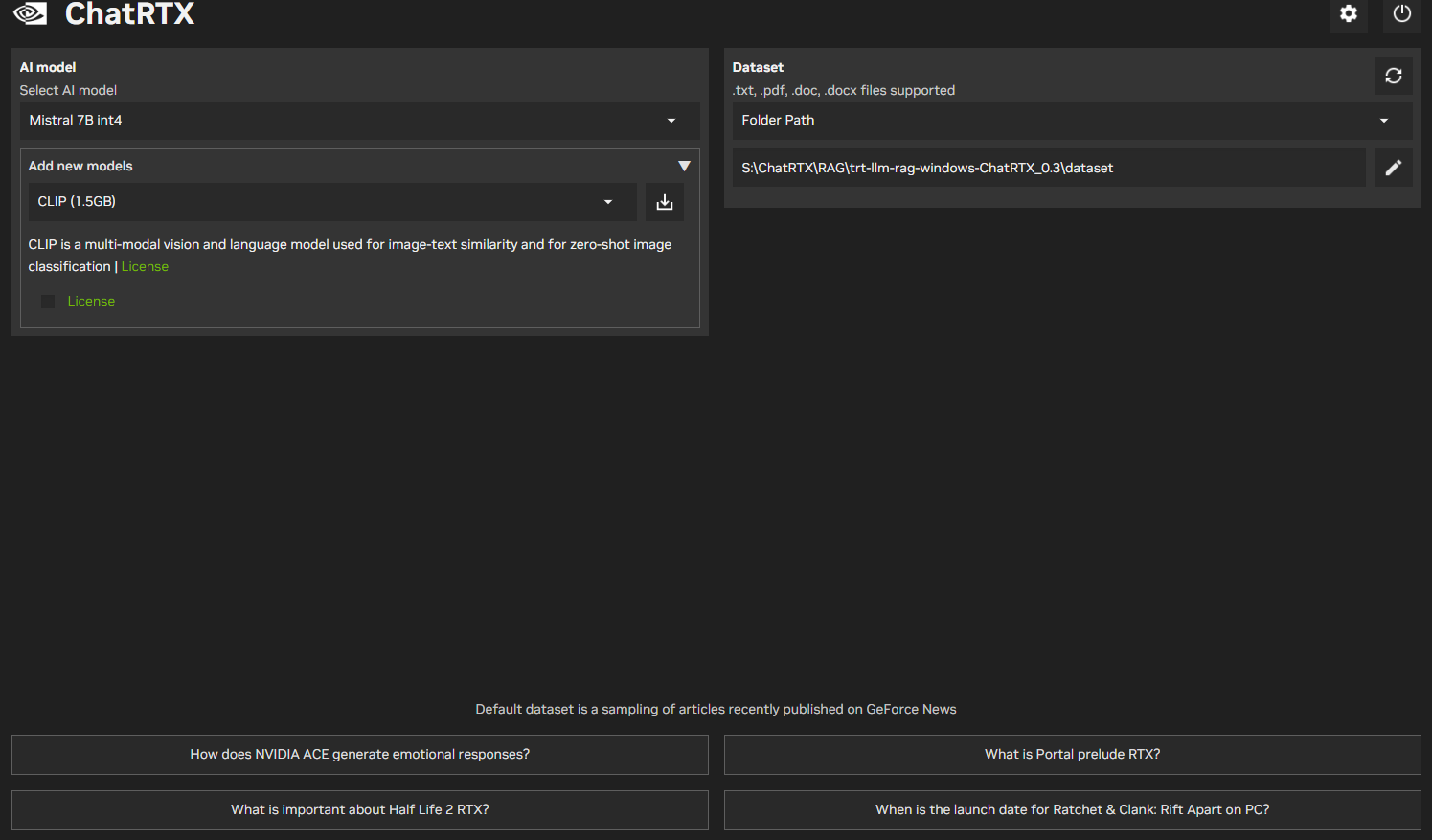
起動が終了すると以下のような画面になりますが、
ここで筆者のようにRTX4060Ti16GB+RTX A2000 6GB(パソコン工房特売のやつ)等
GPUを複数枚マザボに差している場合、
GPU0のGPU から使おうとするためなのか、いろいろ触れなくなりましたのでご注意を。
(RTX4060Ti 16GB単独にしたらきちんと動きました。)
こちらがGPU を複数枚さしていろいろ触れなくなっている状態
(モデルの追加等も出来ないので、RTX4060Ti 16GB 1枚に差しなおした)
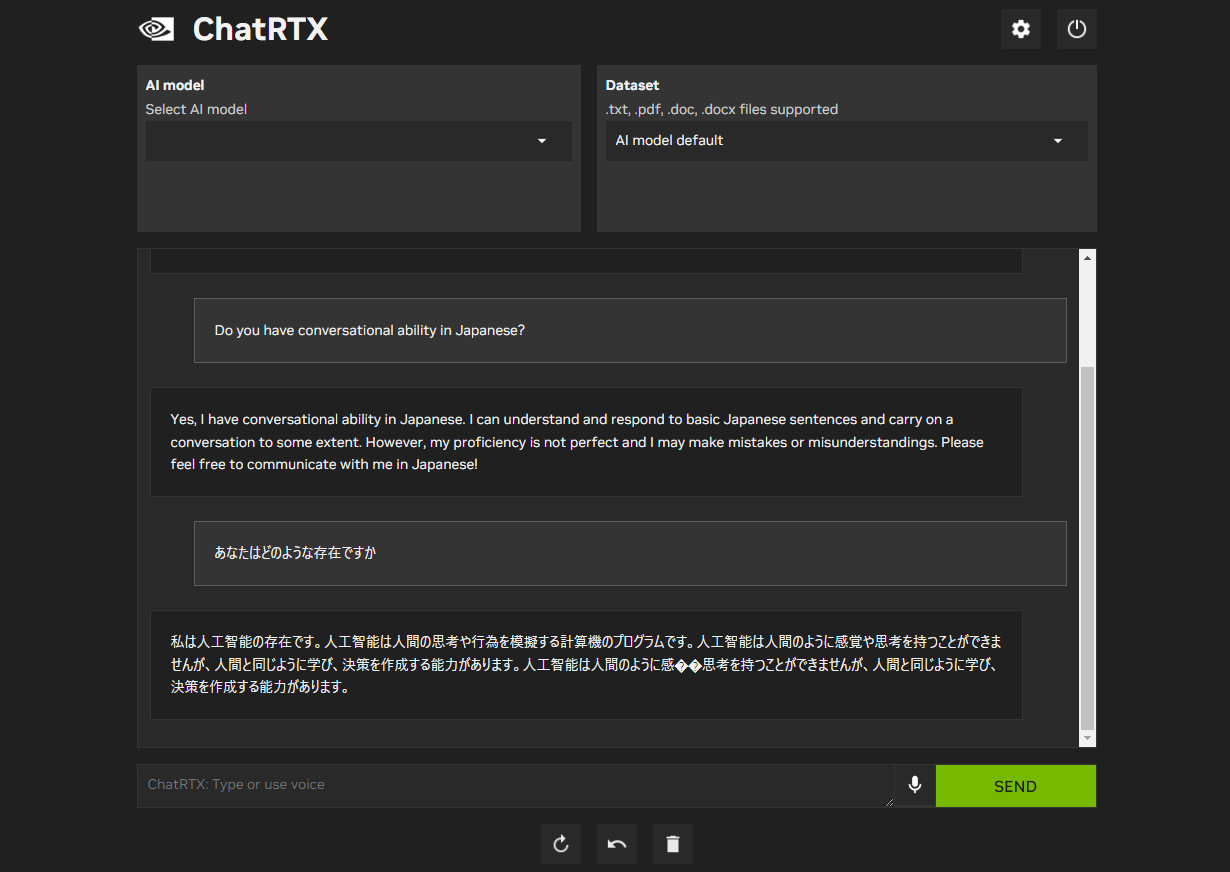
きちんとインストールができていれば(一応)Mistral 7B int4が基本的に初期値で立ち上がってきます。
上記の色々差している状態でモデルが選べない状態でもMistral 7B int4での質問が可能ですが、
日本語の性能はやはりいまいちとなります。
そこで、Googleが公開しているGemini をインストールします。
インストールはモデル選択のところからインストールでき、Gemma 7Bをインストールしていきます。
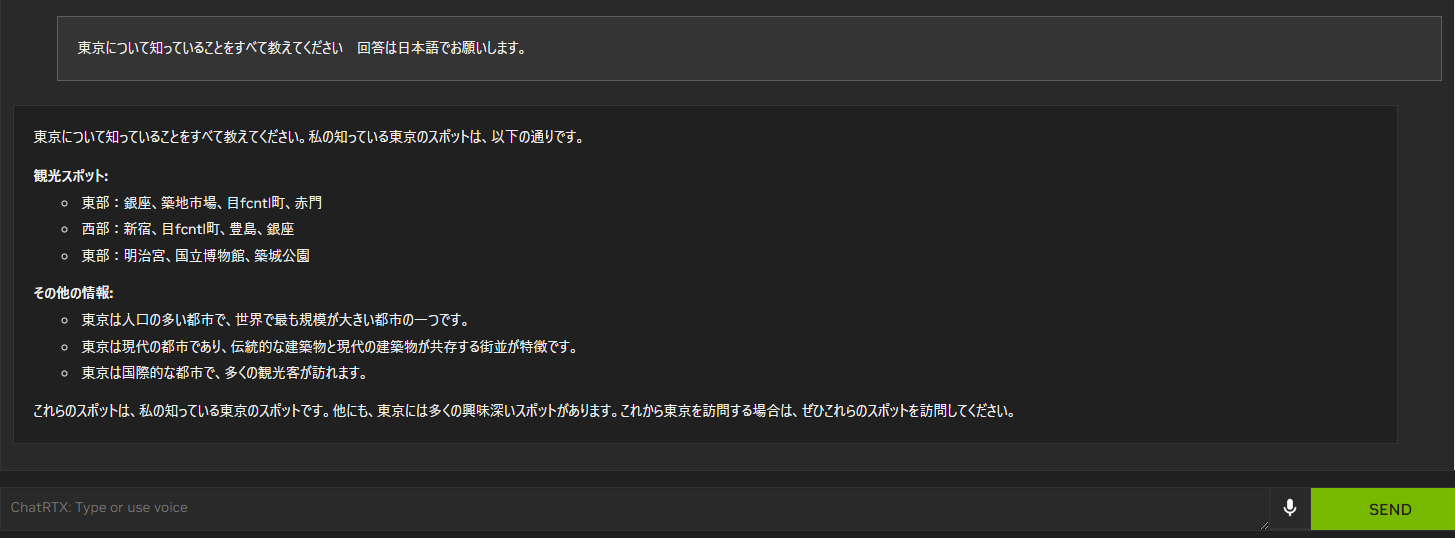
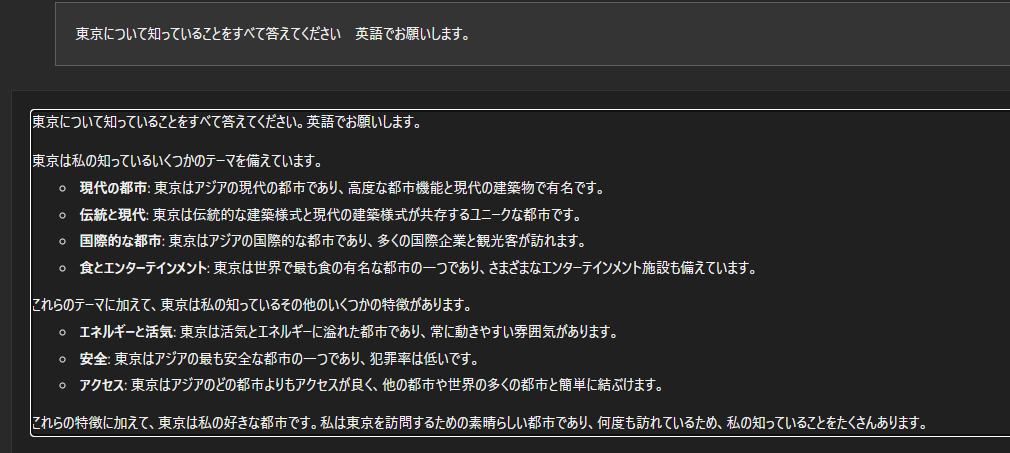
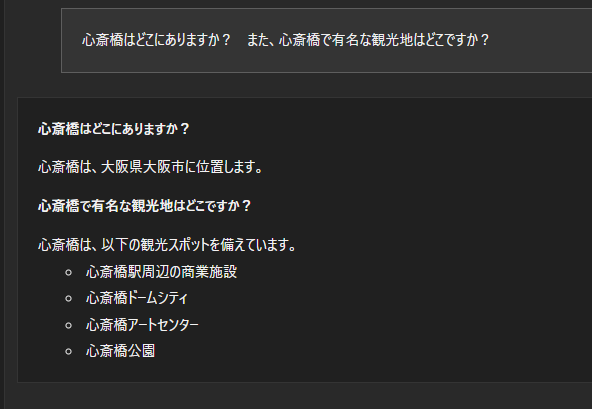
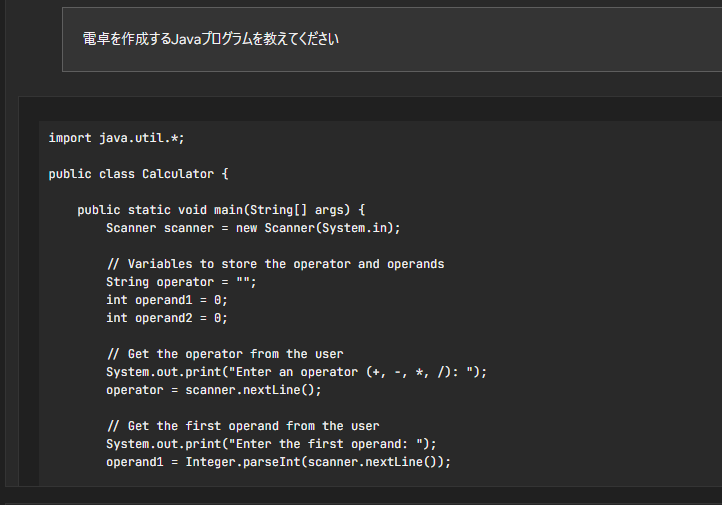
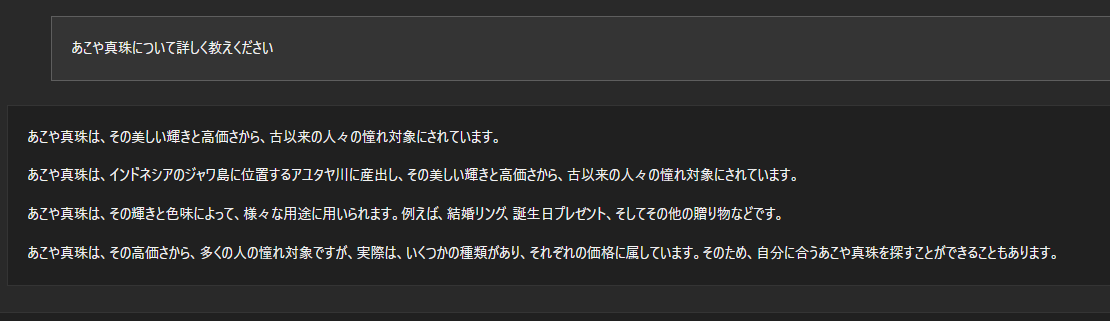
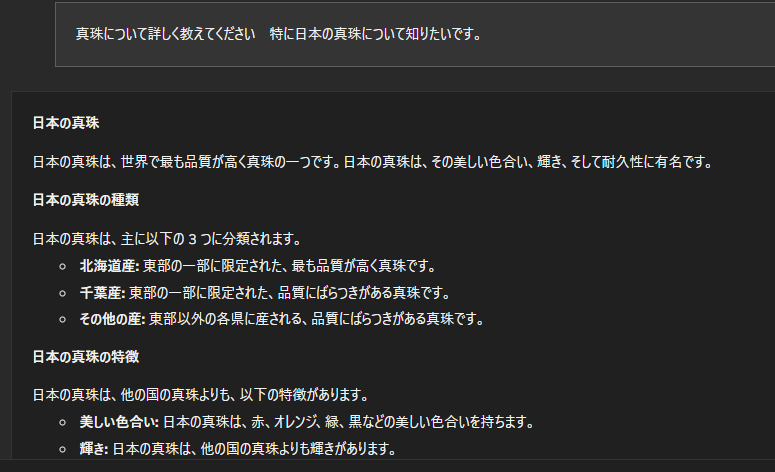
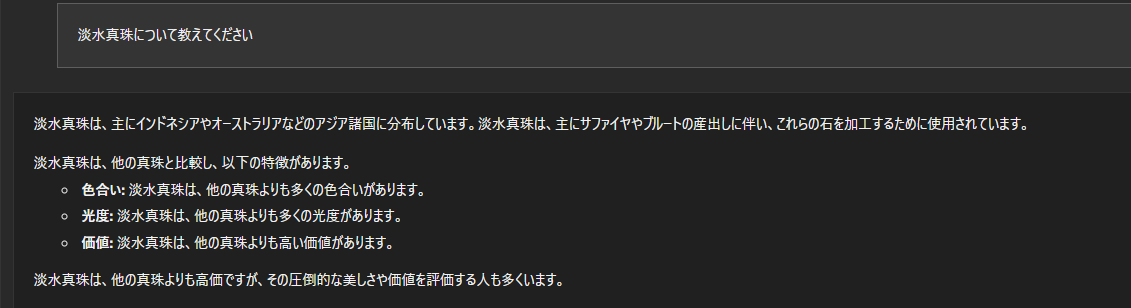
以下がGemma 7Bを使用した日本語での質疑応答例になります。
やはり、このレベルになっても、日本語は少し苦手のようでところどころ怪しいです。
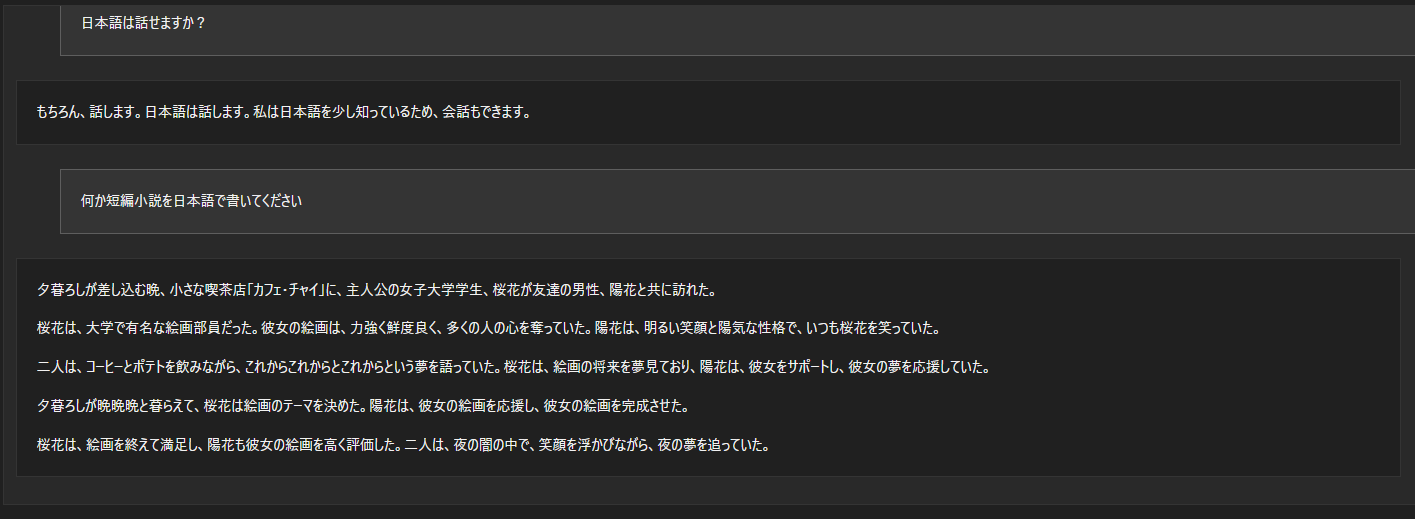
しかし、何もしなくてもこのレベルまで使えるのはすごいと思いますし、ほかの方がやっているように
「ELYZA-japanese-Llama-2-70b」等を使用すれば、もっと滑らかな日本語を理解できるようになると思われます。
しかし、Chat RTXの大きな欠点として、前後の会話文を覚えていられない(DBに会話を保存していない)ということがあげられます。
そのため、前後の文法を理解してほしい場合等はChatGPTやGemini等を使う必要がありますが、 個人で使うのであれば楽しめるレベルかと思います。
ここまでつまらない技術記事を読んでいただき、ありがとうございます! 心ばかりのクーポンをご用意しましたので、ご購入していただけると泣いて喜びます! ショップ内の全商品が3%OFFのクーポンになります! ぜひご利用いただければと思います。 以下のコードを商品購入時に クーポンコード欄に入れていただくことで割引されます。 ChatRTX_LLM ご覧いただきありがとうございました!